
Zollkiesel statt Meilensteine
Digitaler Zettelkasten eines chronisch Neugierigen
Zollkiesel statt Meilensteine
Digitaler Zettelkasten eines chronisch Neugierigen
Ja, ich bin sehr an römischer Geschichte interessiert und mit meinem Vornamen muss so ein Intro einfach sein. 😉 Aber zum Thema. Ich kann es mir an dieser Stelle nicht verkneifen, den “pädagogischen Zeigefinger” an die LuL unter meinen Twitter-Followern zu richten. Seit Jahren erzählen andere Leute und Ich immer wieder, “steckt keine Daten in ein System, aus dem Ihr die Sachen nicht oder nur teilweise wieder rausbekommt!” Was passiert? Alles bauen Padlets als gäbe es kein Morgen. Jetzt kommt mit TaskCards.de eine neue, DSGVO-konforme und Deutschland entwickelte und gehostete Alternative und was passiert. Groß ist das Wehklagen, wie denn jetzt Padlets nach TaskCards konvertiert werden können. Seufz…
Ich grabe aber viel zu gerne in Daten, um eine solche Herausforderung nicht anzunehmen. Schließlich gibt es ja einen CSV-Export für Padlets, kann also nicht so schwer sein…
Ich hätte wissen können, dass dies eher die Suche nach dem heiligen Daten-Gral wird als ein Spaziergang. Also auf zu Schlucht der sichelförmigen Daten. 😆
In einem Padlet kann ich über den Aufruf des Menüs am rechten oberen Eck den Punkt “Exportieren” wählen und dann erhalte ich folgende Auswahl.
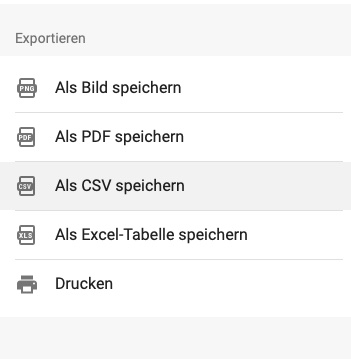
Jetzt auf “Als CSV speichern” klicken und schon habe ich mein Padlet exportiert. Das denken sich Nutzer:innen zumindest, bis diese Datei dann für einen Import auf einer anderen Plattform benutzt werden soll. Ich habe zu Demonstrationszwecken mal ein öffentliches Padlet als CSV exportiert und gekürzt. So sieht das dann aus.
"Änderungswünsche, Ideen, Kritik, neue Kategorien"
Betreff,Text,Anhang,Autor,Erstellt am,Aktualisiert am
"","Hier ist Platz für Rückmeldung.
Gebt Bescheid, wenn Dinge unklar sind, Euch etwas an der Pinnwand stört oder wenn Ihr Verbesserungsideen habt.
Gern auch per E-Mail, wenn Euch das lieber ist:
schule.zu.haus.e@ghg-leipzig.lernsax.de
","",frau_kaden_,2020-04-26 07:11:39 UTC,2020-04-26 13:44:35 UTC
""
Mut-mach-Sprüche & Mut-mach-Bildchen
Betreff,Text,Anhang,Autor,Erstellt am,Aktualisiert am
*Free your mind* Spruch der Woche,"Man sollte viel öfter einen Mutausbruch haben.😉
KA
","",schule*zu*haus*e (schulezuhauseGHG),2020-04-24 10:25:13 UTC,2020-05-13 07:04:53 UTC
"","SK
",https://padlet-uploads.storage.googleapis.com/545994121/0f4831af9b9b84328a9febb808611c1b/media.jpeg,schule*zu*haus*e (schulezuhauseGHG),2020-04-24 23:41:46 UTC,2020-04-26 14:36:53 UTC
Wohlfühlbuch,"Ihr findet hier ein Wohlfühlbuch als pdf-Datei zum Runterladen und Ausdrucken (am besten als Broschüre-Druck, beidseitig, Hochformat, linksbündig).
Wer es in den Händen hält, darin blättert und ab und an mal etwas ausfüllt, kann über sich selbst nachdenken. Das hilft dabei, achtsamer mit sich werden, den Überblick zu behalten und seine Ziele und Träume entspannter zu verfolgen.
An dieser Stelle ein großes Dankeschön an Katrin Pieper vom Kinderschutzbund, die uns dieses Büchlein zur Verfügung gestellt hat.
KA
",https://padlet-uploads.storage.googleapis.com/546076886/26a2cd131cd87d86763cbb59491c91ed/Reflexionstagebuch.pdf,frau_kaden_,2020-04-27 16:11:07 UTC,2020-04-29 20:27:57 UTC
""
Was habe ich aus dieser Zeit über mich gelernt?
Betreff,Text,Anhang,Autor,Erstellt am,Aktualisiert am
"","",https://padlet-uploads.storage.googleapis.com/545994121/f8af32ed570a98a4bb9d7252af14b2f6/media.jpeg,schule*zu*haus*e (schulezuhauseGHG),2020-05-05 21:55:14 UTC,2020-05-05 21:55:27 UTC
""
Das ist nur in Ansätzen das, was ich mir unter einem brauchbaren CSV-Export vorstelle. Nun ist CSV sowieso kein irgendwie standardisiertes Format (nur Excel glaubt das und beharrt bis heute beim Import stur auf seiner Version von CSV 😉), sondern mehr eine Art “Ich habe hier Zeug, das in verschiedene Spalten aufgeteilt ist, die mit irgendeinem Zeichen getrennt sind und machmal können die auch über mehrere Zeilen gehen und ja, es können durchaus auch unterschiedlich viele Spalten pro Zeile sein”.
Ich habe das meditativ einige Minuten betrachtet und schließlich ist der Groschen gefallen. Wer also dieses Format verarbeiten möchte, hier kommt die Beschreibung.
Das Exportformat von Padlet für CSV besitzt folgenden Aufbau:
Mit diesen Informationen kann ich die Datei oben verarbeiten. Das sieht nicht schön aus, aber zumindest an die Kerndaten komme ich ran. Ich möchte aber auch die anderen Informationen wie die Reihenfolge der Karten oder die Bezeichnung des Padlets selbst. Steht alles nicht in der CSV-Datei und den Excel-Export will ich gar nicht erst verarbeiten, Zeug ohne Struktur und Markup aus Excel zu lesen macht graue Haare. 😩
OK, neuer Versuch. Wenn die Exportfunktion nichts sauber rausrücken will, dann muss ich einen anderen Weg finden. Nur wie? Jemand schrieb auf Twitter, “wenn in dem CSV sowieso nicht alles steht, kannst Du das ja aus der WebSite rauskratzen”. Wer jemals sowas versucht hat (oder machen muss), hat spätestens jetzt hochgezogene Augenbrauen. Eine Änderung im HTML-Code und alles geht wieder von vorne los. Das will ich nicht. Aber ja, irgendwo müssen die Daten im Padlet doch herkommen.
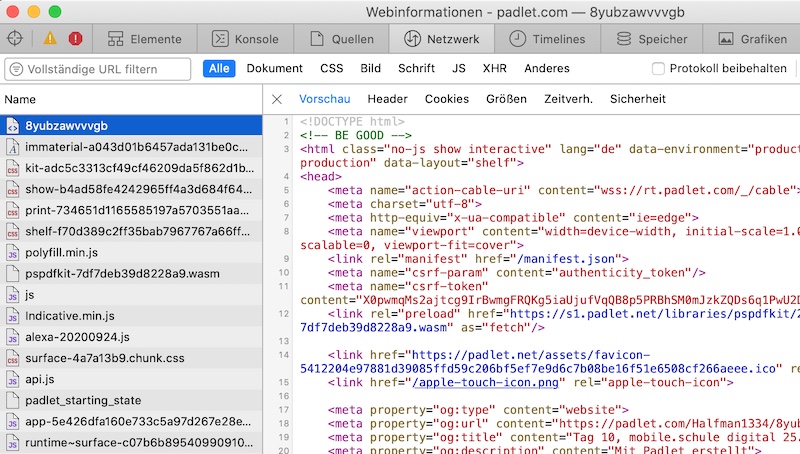
Glücklicherweise gibt es in modernen Browsers die Entwicklerwerkzeuge, mit denen ich dem Browser bei der Arbeit über die Schulter gucken kann.
Die Abbildung oben zeigt zum Beispiel den Netzwerkverkehr, wenn ich eine URL eingebe, also was da alles an Daten angeliefert wird. Als ich mich da neugierig durch die Liste der Einträge klicke und im rechten Teil die Vorschau angucken, stoße auch auf zwei interessante Einträge: wishes und wall_sections.

Was sehe ich da? Die einzelnen Karten des Padlet in all ihrer Pracht und Herrlichkeit, sauber als verarbeitbares JSON und mit deutlich mehr Informationen als der schnöde CSV-Export.
{
"id": "1270393714",
"type": "wish",
"attributes": {
"id": 1270393714,
"wall_id": 29154022,
"published": true,
"row_id": null,
"col_id": null,
"row_span": 1,
"col_span": 1,
"is_content_hidden": false,
"updated_at": "2021-03-04T17:52:51.537Z",
"headline": "Das Iserv Modul BRAINYOO -Quiz, digitale Lernkartei und Vokabeltrainer",
"subject": "Das Iserv Modul BRAINYOO -Quiz, digitale Lernkartei und Vokabeltrainer",
"body": "",
"attachment": "https://youtu.be/Hn0KhckLx-0",
"permalink": "https://padlet.com/Halfman1334/8yubzawvvvgb/wish/1270393714",
"author_id": 1058477297,
"created_at": "2021-03-04T17:50:52.730Z",
"content_updated_at": "2021-03-04T17:52:51.537Z",
"color": null,
"location_point": {},
"location_name": null,
"top": null,
"left": null,
"width": 200,
"position": {
"left": null,
"top": null
},
"sort_index": 143167363847168,
"wall_section_id": 58305136,
"rank": null,
"label": null
}
Ein Beispiel für eine JSON-Darstellung eines Padlet.
Warum diese Dinge bei Padlet intern wishes heißen, würde ich auch gerne wissen. 😄 Aber egal, genau so eine Aufbereitung der Daten für einen Export aus Padlet habe ich gesucht. Also sehe ich mir an, wie (mit welcher URL) diese Ressourcen geladen werden.
wishes https://api.padlet.com/api/5/wishes?wall_id=67685958
wall_section https://padlet.com/api/5/wall_sections?wall_id=67685958
Wie ich mir gedacht hatte. Eine allgemeine URL zur internen API (wie viel leichter wäre das Leben manchmal, wenn die Anbieter von solchen einfach eine sauber dokumentierte API anbieten würden. Aber nein, lieber die Nutzer:innen mit Zähnen und Klauen festhalten) und ein Parameter wall_id, der offenbar angibt, zu welchem Padlet (intern wohl “wall” genannt) die Dinger gehören.
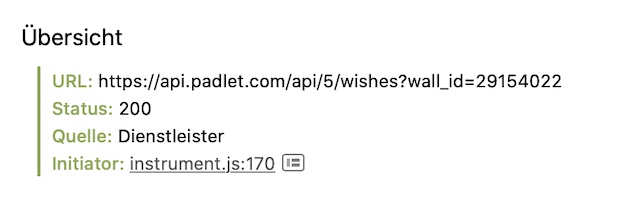
Diese wall_id (warum muss ich immer an den Film “Wall-E” denken? 😉) identifiziert wohl eindeutig ein Padlet. Das ist schön, nur woher bekomme ich diese wall_id für ein Padlet? In der URL zum Padlet steht nur der öffentliche Schlüssel als Identifikation.
Also wieder die Ochsentour und hoffen, dass diese ID nicht intern berechnet wird, sondern irgendwo als Text in all diesen Datendateien steckt.
Beim Durchsuchen der Einträge habe ich einen Treffer in der Datei mit dem Namen padlet-starting-state. Super! Oder doch nicht super?
Zumindest finde ich in dieser Datei alle Informationen zur “Wall”, dem eigentlichen Padlet, ebenfalls schön aufbereitet als JSON.
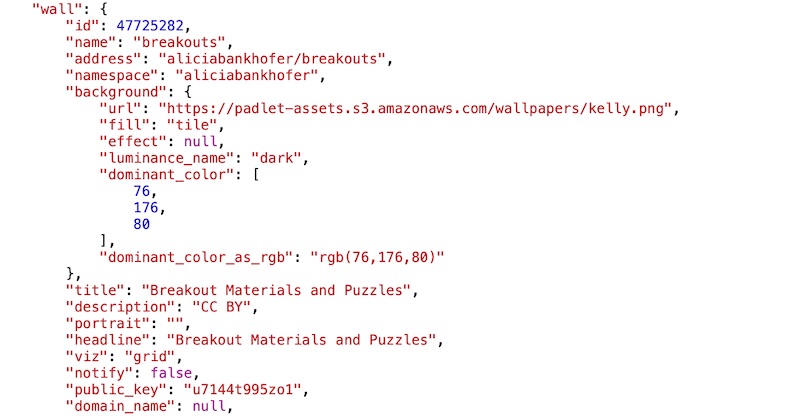
Und da steht auch unter dem Schlüssel die gesuchte ID, super!
:
:
"wall": {
"id": "47725282,
"name": "breaksouts",
:
:
Das war der “Super"-Teil. Jetzt um Teil mit dem “doch nicht so super” 😉 Als ich den Link ansehe, hole ich mir erstmal eine neue Tasse Kaffee…

Das ist erstens lang und zweitens habe ich keine Ahnung wie ich an dieses token in der URL kommen soll. Aber ich habe ja neuen Kaffee, also nochmal auf eine neue Suchrunde durch alle Codes nach dem Token. Ich werde in der Tat fündig und zwar im HTML für die Anzeige, also die eigentliche URL des Padlets, z.B. https://padlet.com/Halfman1334/8yubzawvvvgb.
<link rel="preload" as="fetch" id="starting-state-preload" href="/api/1/padlet_starting_state
?token=QkFoN0J6b01jR0Y1Ykc5aFpIc01PZ3gxYzJWeVgybGthUVNJVmZJcE9neDNZV3hzWDJsa2FRVG0ycndCT2hKcG
MxOW1hWEp6ZEY5MmFXVjNSam9SYVhOZmNtVmhaRjl2Ym14NVJqb1FhWE5mWlcxaVpXUmtaV1JHT2hCaGNuWnZYMk52Ym1
acFozc0hPZ3hqWkc1SWIzTjBTU0laWVhOelpYUnpMbkJoWkd4bGRHTmtiaTVqYjIwR09nWkZWRG9LZEc5clpXNTdCam9Q
YjJGMWRHaFViMnRsYmtraVJXTTNZV016TW1ObFpEZ3hZbVE1TURSaVlqTXhOakJsWVRFNFptUmpPVGd6TlRNMk9UVXpOa
kprWW1Zd1lqWTFNelU1WVROaU5EQTNORGsxT1dFd1ltVUdPdzFVT2cxMWMyVmZZWEoyYjFRNkQyVjRjR2x5WlhOZllYUl
ZPaUJCWTNScGRtVlRkWEJ3YjNKME9qcFVhVzFsVjJsMGFGcHZibVZiQ0VsMU9nbFVhVzFsRFc1S0hzQkc1UzA2Q1RvSmV
tOXVaVWtpQ0ZWVVF3WTdEVVk2RFc1aGJtOWZiblZ0YVFLK0FUb05ibUZ1YjE5a1pXNXBCam9OYzNWaWJXbGpjbThpQjBS
Z1NTSUlWVlJEQmpzTlZFQVAtLWUyNmI0MDlkZjllMmY3MDY5YzVhMTJmZDQ3ZDc2OTUyZDIzMWM5MzI-"/>
Dort im Quellcode steht der Link, in einem <link>-Element mit einer ID. Das macht es leicht, diese Information mit der Funktion getElementById() aus dem Quelltext zu extrahieren und an den Wert des Attributes href zu kommen. Die so über mehrere Hopser gewonnene wall_id wird auch genutzt, um eine Quelle mit dem Namen wall_sections zu laden.
Und siehe da, dort stecken alle Informationen über die “wall section”, also die Listen des Padlets. Hervorragend, hat sich der Kaffee doch gelohnt…
{
"id": "58305136",
"type": "wall_section",
"attributes": {
"id": 58305136,
"title": "Material Slot 1",
"sort_index": -1614327649,
"updated_at": "2021-02-26T08:20:49.722Z",
"created_at": "2021-02-25T09:49:13.534Z",
"color": null
}
},
So, ich fasse das Ganze mal zusammen. Damit sollten alle, die selbst einen Konverter von Padlet nach irgendwohin bauen wollen, genügend Informationen haben, um das zu tun. Folgende Schritte sind nötig:
https://padlet.com/swarzste/uflrgj5mcng0w45opadlet_starting_state laden:
getElementById() das Element mit der ID starting-state-preload extrahieren.href extrahieren und diese URL ladenwall das Objekt laden und dort unter dem Schlüssel id die “wall_id” extrahieren.https://padlet.com/api/5/wall_sections?wall_id=<WALL_ID> laden, wobei <WALL_ID> durch die “wall_id” von oben ersetzt wird.https://api.padlet.com/api/5/wishes?wall_id=<WALL_ID> laden, wobei <WALL_ID> durch die “wall_id” von oben ersetzt wird. Das Ergebnis sind alle Karten des Padlets sauber im JSON-Format.Zuordnung der Karten ("wishes”) zu den Listen über die Schlüssel “wall_section_id” (siehe den Auszug aus dem JSON für eine Karte unten).
{
"id": "823862909",
"type": "wish",
:
:
"attributes": {
"id": 823862909,
"wall_id": 67685958,
"published": true,
"is_content_hidden": false,
"wall_section_id": 23728329,
:
:
}
Es kann in der Tat Padlets geben, die haben keine Listen, da sieht das JSON für die Ressource wall_sections so aus:
{
"data": []
}
Als Wert für wall_section_id steht bei den einzelnen Karten dann der null-Wert.
So, jetzt wünsche ich allen Programmierern viel Spaß beim Exportieren aus Padlet und hoffen wir mal, dass es so schnell kein Update von Padlet mit anderer Logik gibt. Insbesondere das Team von TaskCards.de kann jetzt, wenn es in ihre Roadmap passt, einen direkten Online-Import von Padlet bauen.
Nun denn: “After you, Junior.” – “Yes, Sir!”

Lizenz für diesen Post CC-BY-SA 4.0
