
Ein Daten-Suchspiel für interessierte Lerner
Ich habe kürzlich jemand erklärt, wie sich Datenmengen mit sinnvollen Annahmen für eine Verarbeitung verkleinern lassen. Dazu kam etwas grundlegende Datenanalyse und ein paar andere Dinge. Im Verlauf der Erklärung fiel mir auf, dass sich daraus auch eine interessante Übung für Schülerinnen und Schüler (im Folgenden “SuS”) gestalten lässt und die auch zeigt, dass es weniger auf das verwendete Werkzeug (jedes Werkzeug hat je nach Erfahrung und Kompetenz Vorteile) ankommt als auf die die Person, die das Werkzeug nutzt und die richtigen Fragen stellt und aus einer (ja, das ist realitätsnah 😉) unvollständigen oder harmlos klingenden Erklärung eines Problemraums die richtigen Informationen ziehen kann.
Finde Gianna!
Als Du spät um 2 Uhr morgens nach Hause kommst, findest Du auf Deinem Anrufbeantworter zwei Nachrichten von Gianna, der italienischen Studentin, die Du heute Mittag an der Hochschule in Landshut kennen gelernt hast. Die erste ist eine Nachricht, dass es dunkel ist und sie nicht mehr weiß, wo sie ist und sich verlaufen hat. Kürzer als eine Minute. Die zweite Nachricht ist weniger als eine halbe Minute lang: “Mein Akku ist gleich leer, bitte komm und hole mich, ich sitze im Dunkeln auf einer Parkbank!” Offenbar hat sie sich verirrt und braucht Deine Hilfe. Zurückrufen fällt also aus und der Anrufbeantworter zeigt auch keine Nummern an. Du weißt aber, dass sie hier in Deutschland auch mit ihrer italienischen SIM-Karte im Smartphone unterwegs ist, also mit einer italienischen Vorwahl ankommt. Glücklicherweise bist Du schlau und kennst Dich mit Computern aus. Nach ein paar Minuten hast Du Zugriff auf eine Datei mit allen Telefonverbindungen des Tages in Südbayern. Das sind allerdings über 24000 Einträge, die kannst Du unmöglich per Hand durchgehen und an jede dort gespeicherte Position fahren. Alles, was Du aktuell über ihren Aufenthaltsort weißt: sie muss in der Gegend von Landshut sein. Du musst die die richtigen Fragen stellen, um die Menge der Daten zu verringern. Kannst Du Gianna finden?
Die Datei mit den Telefonverbindungen ist eine CSV-Datei (also eine Textdatei, bei der die Datenspalten durch ein bestimmtes Zeichen getrennt sind). Jede Zeile enthält einen Datensatz, der aus den folgenden Feldern besteht:
- CCP ("country code prefix"),
die internationale Telefonvorwahl für das Land, aus dem die Nummer kommt - UID ("unique id),
da wir keine echten Telefonnummern für dieses Spiel verwenden, dient diese Zeichenkette als Identifikation - TIM ("time of call"),
der Zeitpunkt der Verbindung als Zeichenkette - HRS ("hour"),
die Stunde als einzelnes Datenfeld für eine leichtere Verarbeitung bei Bedarf - MIN ("minutes"),
die Minuten als einzelnes Datenfeld für eine leichtere Verarbeitung bei Bedarf - SEC ("seconds"),
die Sekunden als einzelnes Datenfeld für eine leichtere Verarbeitung bei Bedarf - DUR ("duration"),
die Länge der Verbindung in Sekunden - LAT ("latitude"),
der Breitengrad der geografischen Position, die das Telefon gesendet hat - LON ("longitude"),
der Längengrad der geografischen Position, die das Telefon gesendet hat
Die erste Zeile der Datei enthält diese Spaltenbezeichnungen und jedes Datenfeld ist durch ein Semikolon getrennt. So sehen die ersten drei Zeilen der Datei aus:
CCP;UID;TIM;HRS;MIN;SEC;DUR;LAT;LON
49;f26ca40e-06c2-4778-ab39-132b079f579d;00:00:06;0;0;6;617;48.4515;12.7086
41;a93f436c-000e-4c48-8087-14f5c9d1871e;00:00:10;0;0;10;1143;49.8089;12.9944
(für die Profis unter Euch in Kurzform: CSV-Datei, Trenner ist “;”, Zeilentrenner windows-freundlich CR/LF, Kodierung ASCII) 😉
Damit Ihr zum Ausprobieren nicht lange rumbasteln müsst, findet Ihr die unkomprimierte Datei hinter diesem Link. Die Daten in der Datei sind chronologisch geordnet. Diese Datei besitzt, wie oben bereits geschrieben, mehr als 24500 Zeilen, ein einfaches Durchklicken oder Durchblättern ist also kein Lösungsansatz. Es gibt viele verschiedene Wege zum Ziel mit vielen verschiedenen Werkzeugen und Ansätzen, daher ist jeder Weg der Richtige, wenn er Dich zu Gianna führt. Ich kann weiter unten also nur beispielhaft einige mögliche Wege zeigen.
Update: für alle, die mit Numbers oder Excel arbeiten wollen, habe ich unter diesem Link die Datei im Excel-Format ergänzt. Dann spart Ihr Euch die Konvertierarbeit.
Zuerst müssen wir diese Daten also verarbeiten. CSV-Dateien sind das “simple bad English” der IT, können also nahezu überall verarbeitet oder eingelesen werden. Ich habe deshalb auch den Zeilentrenner bei einem für Windows freundlichen CR/LF gelassen (unter Linux, *nix und Co und auch auf dem Mac ist das üblicherweise LF). Der Spaltentrenner von “;” (Semikolon). Ein Import in irgendein Tool oder die Verarbeitung auf der Kommandozeile ist also kein Problem.
Wenn Du die Lösung findest, erhältst Du zwei Datenzeilen, die Dir den Weg zu Gianna zeigen.
Wenn Du einen anderen, interessanten Weg gefunden hast, schreib einen Kommentar oder mir eine Mail oder kontaktiere mich auf Mastodon, dann kann ich das hier einbauen!
Lösungsansätze
In sehr vielen Crime-Serien werden immer irgendwelche “Hacker” oder “Häcksen” gezeigt, die dem Team in Sekundenschnelle mit Computerzauberei aus einem irrsinnig großen Berg an Daten die eine Information herausklauben, die mithilft, den Fall zu lösen. Ich möchte mit diesem Blogpost bzw. dieser Übung zeigen, dass dies ein Körnchen Wahrheit enthält, nämlich dass es darauf ankommt, bei der Analyse von Daten die richtigen Fragen zu stellen. Daten sind noch keine Informationen und um aus Informationen Wissen zu machen, braucht es erst einmal Wissen bzw. Fähigkeiten beim “Ermittlungs-Team”. 😄
Was haben wir denn?
Eine Suche nach einem Bereich innerhalb der ungefähren Koordinaten von Landshut (48.50 bis 48.60 N und 12.00 bis 12.25 E) wäre eine Möglichkeit (und ich habe die Daten auch so gebaut, dass da nicht gleich Tausende Datensätze rauskommen), aber es geht mit den Daten und der Information aus dem Text noch besser.
- Wir haben zwei Anrufe, beide sind kürzer als eine Minute und der zweite ist kürzer als der erste
- “Es ist dunkel”, die Anrufe müssen also spät am Abend gewesen sein
- Gianna hat ein italienische SIM-Karte, also eine Ländervorwahl von “39”
- Dazu kommen die Koordinaten (wir vermuten aber nur, dass Gianna in der Gegend von Landshut ist)
Bevor jemand von Euch versehentlich einen Spoiler liest, werde ich hier mal etwas “Leerraum” einbauen. Wer also die Lösung sehen will, einfach etwas nach unten scrollen…
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Tabellenkalkulation
Eine Möglichkeit ist es, den Datenbestand in eine Tabellenkalkulation zu importieren und dann die entsprechenden Datenzeilen durch Filtern heraus finden.
Die praktische Schwierigkeit dabei ist, dass viele Tabellenkalkulationen nicht gerade gut mit dem Import von CSV-Daten umgehen können bzw. Daten dann oft nach eigenen Vorstellungen umformatieren (wer nicht glaubt, dass gerade Excel hierbei besonders “kreativ” ist, sollten diesen Artikel lesen). Eine rühmliche Ausnahme ist hier LibreOffice, das auch bei großen Dateien und unkonventionellen Formaten eine gute Figur macht und mein Programm der Wahl für solche Aufgaben ist, wenn es eine Tabellenkalkulation sein muss.
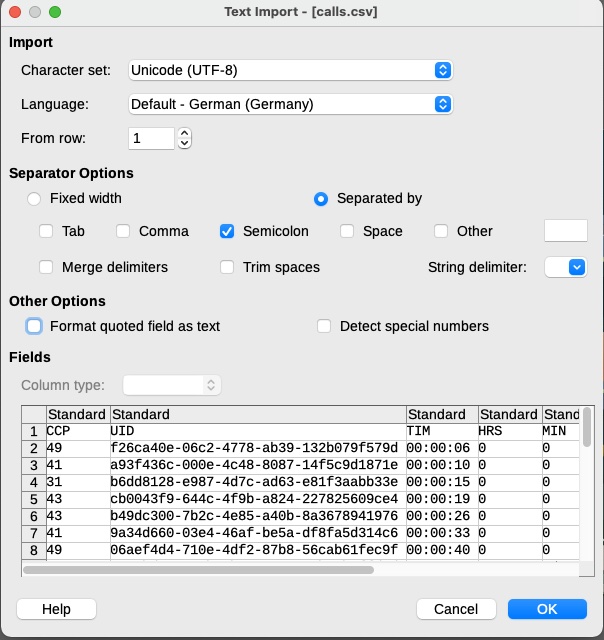
Mit diesem Dialog lassen sich auch seltsame CSV-Dateien sauber importieren.
Nun muss nur noch über das Menü “Daten” ein Standardfilter gesetzt werden und die Filterbedingungen werden eingetragen:
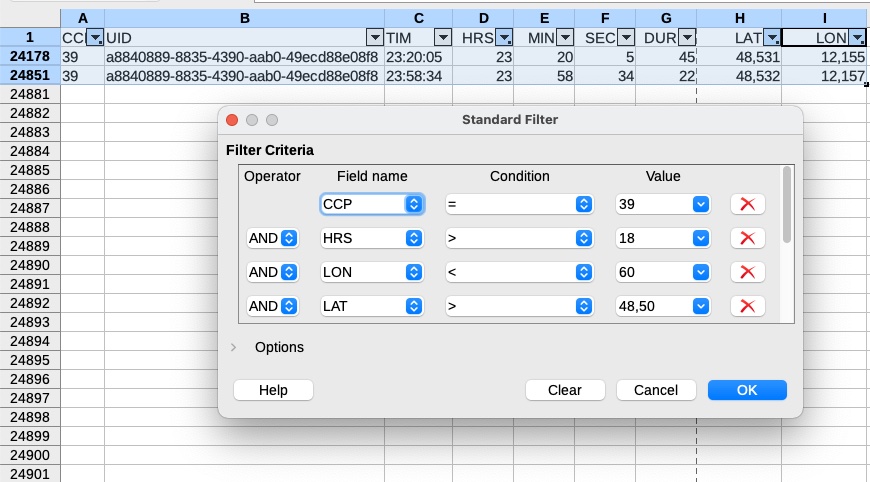
Wie gesagt, wer das mit Excel und seiner eigenwilligen Vorstellung von CSV-Support versuchen möchte, darf das gerne versuchen. 😉
Datenbank
Die CSV-Datei in eine Datenbank zu importieren, ist das nicht aufwändig? Nicht unbedingt, denn es gibt einen Weg, der sogar nur mit dem Browser auskommt und daher “unterrichtsfreundlich” ist. Wir benutzen https://sqliteonline.com, eine browser-basierte Umgebung für die SQL-Datenbank SQLite.
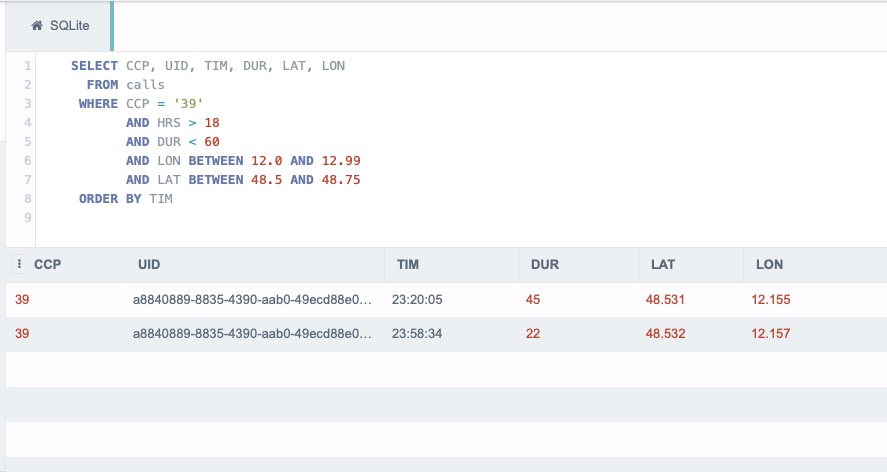
Dort lässt sich ohne Registrierung die CSV-Datei importieren und dann hast Du eine komplette SQL-Datenbank im Browser. Sehr schick. Der Rest ist dann nur noch die Formulierung der Bedingungen, die wir wissen, als eine SQL-Abfrage:
SELECT CCP, UID, TIM, DUR, LAT, LON
FROM calls
WHERE CCP = '39'
AND HRS > 18
AND DUR < 60
AND LON BETWEEN 12.0 AND 12.99
AND LAT BETWEEN 48.5 AND 48.75
ORDER BY TIM
Schon bekommen wir die beiden Datensätze, die uns zeigen, wo sich Gianna befindet.
Programm
Herzlichen Dank an Raphael Wimmer, der mit innerhalb kürzester Zeit eine Lösung zugesandt hat, die das Ergebnis mit Hilfe eines kurzen Python-Scripts findet und dabei die Dienste von OpenStreetMap nutzt. Zeigt meiner Meinung sehr schön, warum Python im Umfeld von data science so beliebt ist, Du kommst unheimlich schnell zu Ergebnissen.
Raphael stellt den Code der Allgemeinheit unter einer CC0-Lizenz zur Verfügung. Ihr könnt also nach Herzenslust rumbasteln.
Danke, Raphael!
import pandas as pd
import requests as rq
from collections import Counter
# Code von https://twitter.com/RaphaelWimmer
# Was wir wissen:
CSV = "https://arminhanisch.de/2021/08/finde-gianna/calls.csv"
ORT = "Landshut"
BUNDESLAND = "Bayern" # sicherhheitshalber
LAND = "Deutschland"
ANRUF_NACH = "16:00:00" # frühestens dann wird es dunkel
# CSV holen
df = pd.read_csv(CSV, delimiter=";")
# Bounding Box (umgebendes Rechteck) von Landshut holen
reply = rq.get(f"https://nominatim.openstreetmap.org/search.php?city={ORT}&state={BUNDESLAND}&country={LAND}&format=jsonv2")
bb = reply.json()[0]['boundingbox']
# alle Anrufe, die innerhalb der Bounding Box sind
df_in_landshut = df[df['LAT'].between(float(bb[0]), float(bb[1]))] \
[df['LON'].between(float(bb[2]), float(bb[3]))]
# Alle Anrufe dort nach 16:00 Uhr
callers = Counter(df_in_landshut[df['TIM'] > ANRUF_NACH]['UID'].values)
# Wer davon hat mehr als einmal angerufen (ist nur eine Person)
numbers = [num[0] for num in callers.most_common() if num[1] > 1]
# Gianna's Nummer
print("Giannas Nummer: " + numbers[0])
# Wo war Gianna zuletzt?
gianna = df[df['UID'] == numbers[0]]
lat = gianna['LAT'].values[-1]
lon = gianna['LON'].values[-1]
print(f"Gianna ist hier: {lat}, {lon}")
# Adresse laut OpenStreetMap
giannas_location = rq.get(f"https://nominatim.openstreetmap.org/search.php?q={lat}%2C+{lon}&format=jsonv2")
print("Adresse: " + giannas_location.json()[0]['display_name'])
Die Kommandozeile
Wer mich kennt, weiß natürlich, dass ich bei sowas auf keinen Falls auf einen Lösungsansatz verzichten werde, die die Kommandozeile beinhaltet. 😄
Die Filterbedingung schreiben wir in eine Textdatei, damit sich diese leichter ändern lässt (ich nenne diese hier filter.awk. Diese besitzt den folgenden Inhalt und listet ebenRandbedingungenfalls nur die oben bekannten Randbedingungen in der awk-Syntax auf (wer eine Programmiersprache mit einer Verwandtschaft zu C kennt, findet die Syntax gleich vertraut).
$1 == "39" \
&& $4 > 18 \
&& $7 < 60 \
&& $8 > 48.5 && $8 < 48.6 \
&& $9 > 12.0 && $9 < 12.25
Das Tool awk nutzt als Standard-Trenner zwischen Datenspalten den Tabulator, also müssen wir mit der Option -F ";" dafür sorgen,
dass das Semikolon als Trennzeichen erkannt wird. Dazu kommt noch eine Besonderheit, die schon ganze Heerscharen von Leuten in den Wahnsinn trieb, die mit Daten arbeiten: das Dezimaltrennzeichen! Das ist in der Dezimalpunkt, auf meinem Mac, der auf Deutsch eingestellt ist, ist das Trennzeichen aber das Dezimalkomma. 🤪 Daher muss vor dem Aufruf von awk die Umgebungsvariable LANG für die Ausführung auf einen Wert gesetzt werden, der einen Dezimalpunkt verwendet LANG=en_US.UTF-8.
Der Aufruf von awk sieht dann so aus:
LANG=en_US.UTF-8 awk -F ";" -f filter.awk calls.csv
Alternativ hätte ich auch die Dezimalpunkte in der Datei durch ein Komma ersetzen können (z.B. mit dem Kommando tr).
Das Ergebnis ist wiederum das Gleiche wie bei den anderen Ansätzen:
39;a8840889-8835-4390-aab0-49ecd88e08f8;23:20:05;23;20;5;45;48.531;12.155
39;a8840889-8835-4390-aab0-49ecd88e08f8;23:58:34;23;58;34;22;48.532;12.157
Kennst Du noch einen anderen Weg?
Ich hoffe, es war eine interessante mentale Fitnessübung! Falls Du noch einen anderen Weg gefunden hast, dann lass es mich wissen, ich ergänze das dann, wenn es neue Lösungsmöglichkeiten zeigt.